

参考文献:
https://www.mdpi.com/2072-4292/15/8/2014
Xu, J.; Yang, J.; Xiong, X.; Li, H.; Huang, J.; Ting, K.; Ying, Y.; Lin, T. Towards Interpreting Multi-Temporal Deep Learning Models in Crop Mapping.Remote Sens. Environ.2021,264, 112599. [CrossRef]
102.Tian, H.; Wang, P.; Tansey, K.; Han, D.; Zhang, J.; Zhang, S.; Li, H. A Deep Learning Framework under Attention Mechanism for Wheat Yield Estimation Using Remotely Sensed Indices in the Guanzhong Plain, Pr China.Int. J. Appl. Earth Obs. Geoinf.2021, 102, 102375. [CrossRef]
带有注意力机制的 LSTM 模型被用来提高产量预测模型的通用性,并确定不同变量对产量的贡献 [ 102 ]。
Reedha 等人 [ 131 ] 使用 Visual Transformer (ViT) 模型对无人机拍摄的航拍图像进行分类,并实现了与 CNN 类似的准确度。作者还声称,当标记的训练数据集较小时,ViT 模型可以比最先进的 CNN 分类更好。为了评估其性能,DL 模型通常与 ML 方法(例如 SVM、RF 和 DT)进行基准测试。
论文来源:
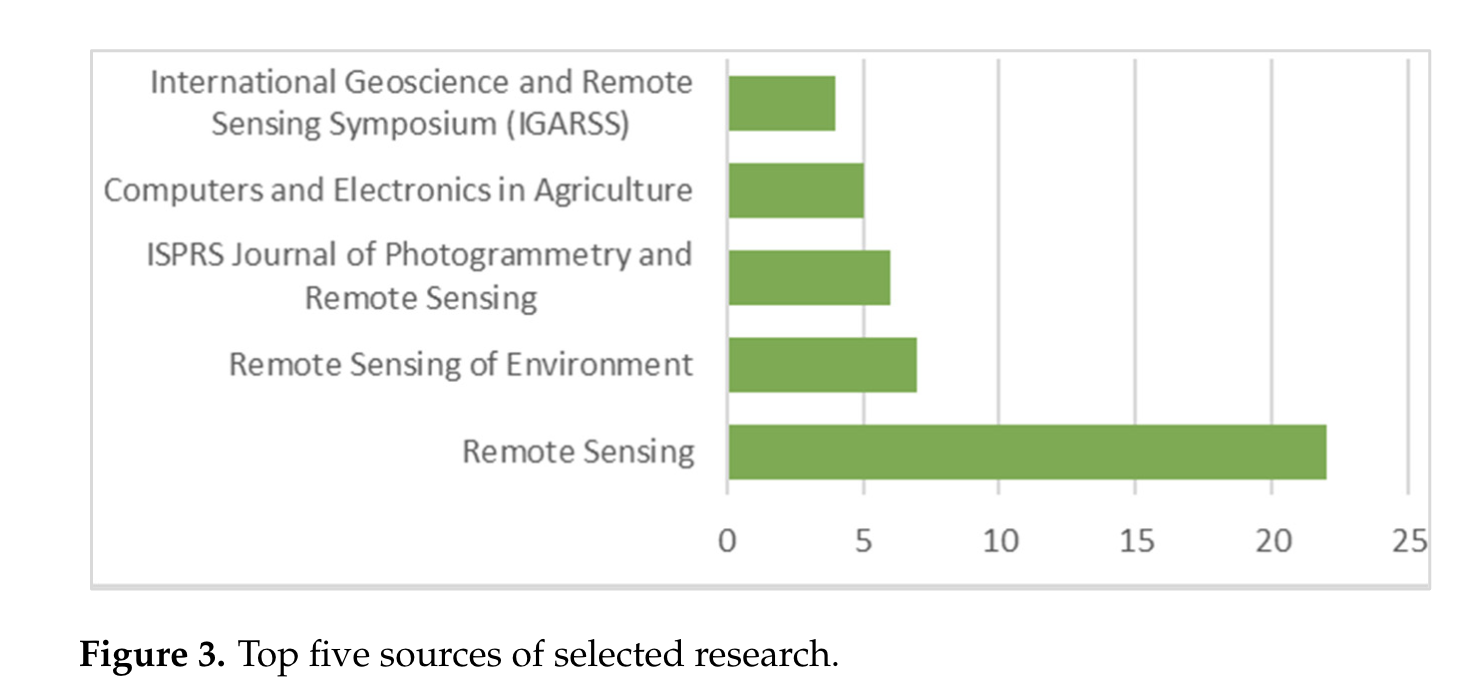
4.1. 所用传感器和平台。
卫星、航空或无人机传感器可用于获取遥感数据,以进行作物测绘和产量预测。如图5所示,大约 81% 的作物测绘和产量预测研究使用了卫星传感器,其次是无人机(12%)。一些作物测绘研究(四项)也主要使用卫星和航空图像来测试其开发的模型的稳健性。卫星图像易于获取,因为卫星已经存在于太空中并定期捕获数据。此外,数据提供商会对卫星图像进行初步预处理。因此,用户可以专注于应用程序的开发,而不是预处理部分。无人机在产量预测研究[72、73、74、75、76、77]中的使用频率高于作物测绘研究,尽管无人机在提供精确作物边界测绘数据方面同样有用。
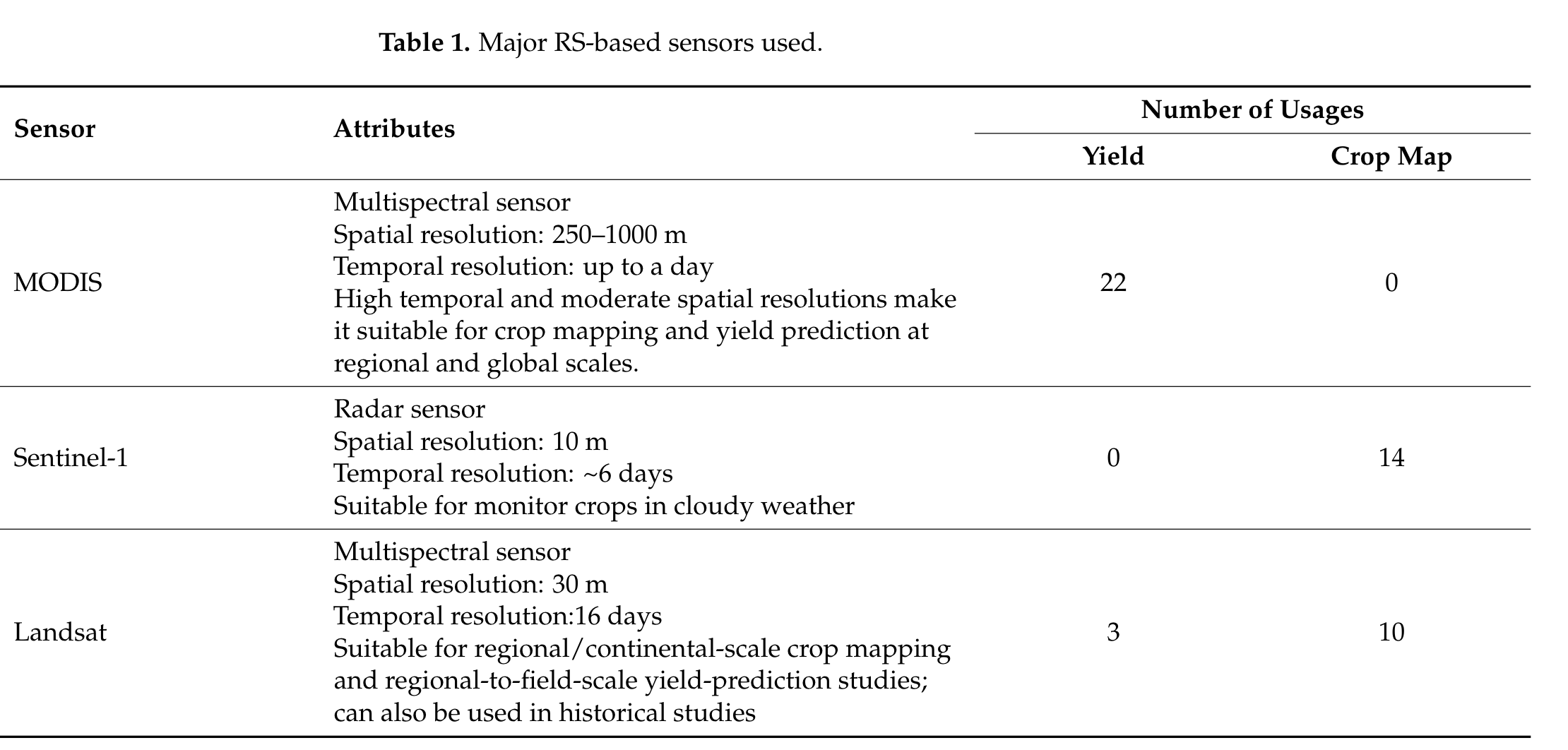
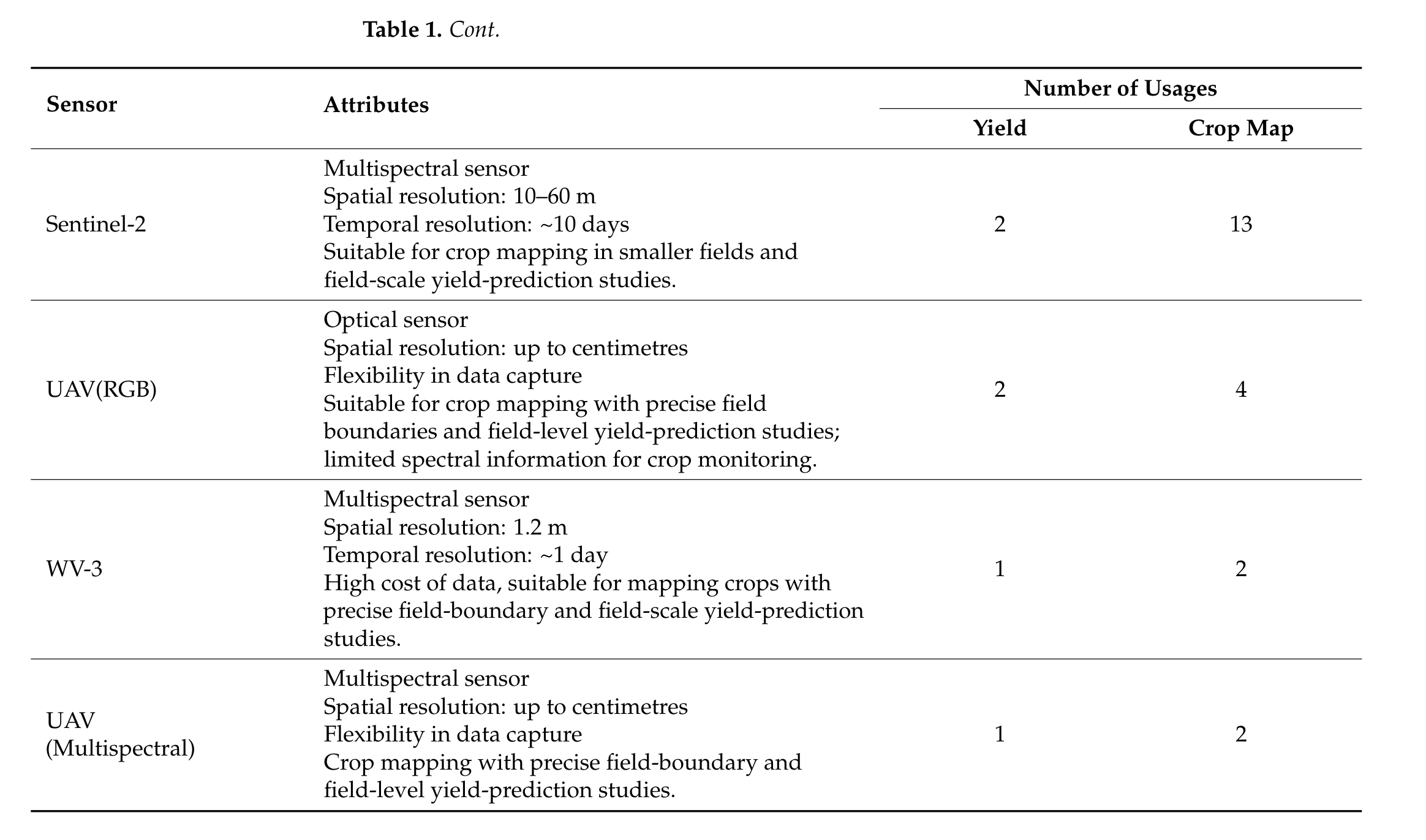
表 1总结了作物测绘和产量预测研究中使用的主要传感器。
除了表中提到的传感器外,
Planet-Scope、AVHRR、基于 UAV 的高光谱和基于 UAV 的多光谱 (MS) 和热传感器也用于一些产量预测研究,
而 Quickbird、SPOT、VENμS、OHS-2A、Planetscope、RADARSAT-2、EO-1 Hyperion、Formosat-2、GF-1、DigitalGlobe、ROSIS-03、WV-2、NAIP、RapidEye、Aerial (UCMerced) 和 Aerial (高光谱) 也用于作物测绘研究。
中分辨率成像光谱仪 (MODIS) 是最常用的传感器,专门用于产量预测研究。区域研究中的高时间和足够的空间分辨率可能使 MODIS 成为区域级产量预测研究的首选。
Sentinel-1、Landsat 和 Sentinel-2 是作物测绘研究中最常用的传感器。
。
所有上述遥感数据的共同优点是它们都可以免费获取。这些数据也可以通过谷歌地球引擎获取,因此可以进行数据管理和预处理。
事实上,一些作物监测研究已经使用谷歌地球引擎作为数据管理和处理平台 [78,79,80 ]。MODIS 和Sentinel传感器的高时间分辨率还可以让我们在更精细的层面上研究作物物候学。
Sentinel-1 和Radarsat -2 等雷达传感器也可以在多云天气下工作。这可能是这些传感器在包括水稻在内的作物物候特征研究中得到更广泛应用的原因。
基于无人机的光学和多光谱传感器的数量也相当可观。
。
值得注意的是,尽管高光谱传感器能够提供更好的光谱范围和精度,而这正是作物监测所必需的[ 81 ],但对其的探索较少。
4.2 输入特征
作为深度学习架构的特征输入,作物制图研究通常使用光学数据(RGB)、多光谱数据、雷达数据、热数据或这些数据的组合。
一些已综述的研究使用从遥感数据中得出的时间序列增强植被指数(EVI)[ 82、83 ]和 归一化差异植被指数[ 84 ] 作为其作物制图模型的输入。
Bhosle 和 Musande[ 85 ]在将高光谱图像输入 CNN 模型之前,使用主成分分析降低了其维数。(高光谱降低维数)

(将 CNN 用于遥感应用要怎么做)传统上,计算机视觉 CNN 模型是针对三通道红、绿、蓝(RGB)图像设计的。在将为计算机视觉开发的传输模型用于遥感应用时,数据应以三通道 RGB 格式准备,**因此不能使用额外的多光谱波段[ 86** ]。(为什么啊?)例如,Li 等人[ 87 ]采用了这种方法,只使用多光谱 Quickbird 图像的 RGB 通道来输入 LeNet 模型。

。
。
(作物产量研究的 输入特征)
对于作物产量研究,气候和土壤数据等环境数据越来越多地与遥感数据相结合[ 88,89,90,91,92,93,94,95,96 ] 。
光学、多光谱、雷达或热数据,或它们的组合,是产量预测研究中常用的遥感输入特征。
植被指数在产量预测研究中的使用频率高于在测绘研究中。大约40 %的产量预测研究使用植被指数作为其模型的输入。
(这里大概是说光学或/和多光谱图像作为输入特征效果好)然而,Nevavuori、Narra 和 Lipping[ 73 ]和 Yang 等人[ 74 ]发现,在 CNN 模型中,光学或/和多光谱图像 比 植被指数对产量的预测效果更好。
[ 90 ]的作者尝试使用卫星获取的气候和土壤数据来预测产量,而不使用光谱或VI信息(VI(Vegetation Index,植被指数)),但该模型仅实现了0.55的判定系数。(决定系数(coefficient of determination),通常用 R² 表示,是用于评估回归模型拟合优度的指标。R² 的取值范围在 0 到 1 之间,越接近 1 表示模型对数据的拟合越好,预测能力越强。)
。
。
(在行政单位(县/区)尺度的作物产量预测研究)在行政单位(县/区)尺度的作物产量预测研究中,卫星图像的分辨率高于目标数据。
在这种情况下,一种典型的方法是使用平均值或加权平均值汇总每个目标区域(县/区)的值。
You 等 [ 42 ][提出了一种直方图方法来降低 RS (遥感数据)数据的维数](https://www.mdpi.com/2072-4292/15/8/2014#B42-remotesensing-15-02014),同时保留产量预测的关键信息。该方法被随后的几项研究采用 [ 5、78、97 ]。
。
。
(多时态数据)多时态数据对于区分作物类型和可靠估算产量必不可少,它可以捕捉作物不同生长阶段的信息 98,99,100 [] 。
有趣的是,在 59% 的研究中,输入特征具有多时间维度。
(缺陷)虽然许多研究使用多时间数据,但没有一项研究直观地模拟时间依赖性。
一些研究使用 “可解释人工智能 (XAI)” 技术来了解不同输入特征在模型预测中的重要性。例如,Wolanin 等人 [ 101 ]使用回归-激活映射可视化和解释特征和产量驱动因素,以确定不同驱动因素对产量预测研究的影响。他们发现,向下的短波辐射通量是产量预测中最有影响力的气象变量。他们还利用注意力机制确定了影响产量的最重要变量 [ 102 ]。通过可解释性分析,Xu 等人[ 103 ] 发现时间序列长度的增加提高了季节分类场景中的分类置信度。
4.3 架构
深度学习作物制图和产量预测应用通常使用卷积神经网络(CNN)、循环神经网络(RNN)、深度神经网络(DNN)、自编码器(AEs)、Transformer 以及混合架构构建(表2)。
CNN 是最流行的架构,在大约58%的被审查研究中得到使用。CNN 架构更适合于数组数据,如遥感数据。
Kuwata 和 Shibasaki [104]是使用深度学习进行作物产量估计领域的先驱者之一。他们使用具有单个和两个全连接层(内积层)的 CNN 网络来提取影响作物产量的特征并估计产量指数。他们将卫星、气候和环境数据用作模型的输入。
类似地,对于作物制图,Nogueira 等人[105]应用了一种早期方法,他们使用 CNN 从遥感场景中提取特征,并将场景分类为coffee和non-coffee。
Kussul 等人[106]在一项开创性工作中提出了一种基于 CNN 的模型,用于对多时态、多源遥感数据进行分类以进行作物制图。

基于卷积神经网络(CNN)的方法在语义分割中的应用可以大致分为基于图像块的方法和全卷积网络(FCN)[107]。
(基于图像块的方法)
在基于图像块的方法中,图像被切成不同的图像块。每个图像块被输入到CNN模型中,该模型将中心像素或整个图像块分配给一个目标值。(例子)基于图像块的CNN在作物制图中的一些例子包括Kussul等人的二维CNN分类模型[106]、油棕榈树和柑橘树检测研究[87,108,109]、Chen和Tao对极化合成孔径雷达(PolSAR)数据的分类[110]以及Nogueira、Miranda和Santos的研究[105],他们将SPOT图像场景分类为咖啡场景和非咖啡场景。
(Tri 等[ 75 ])在产量预测中,Tri 等[ 75 ]使用 LeNet 和 inception 版本 从图像块中提取特征。
在 inception 模块中,不是选择滤波器大小,而是选择多个不同大小的卷积滤波器(以学习不同尺度的特征),并将所有输出连接起来 [ 111 ]。
为了减少参数数量,沿深度使用了一对一卷积。
(Nevavuori 等[ 80 ])Nevavuori 等[ 80 ]设计了一种类似于 Krizhevsky 等[ 46 ]提出的 CNN 架构,用于根据基于无人机的 RGB 图像预测产量。该模型以令人满意的准确度预测了田间小麦和大麦的产量。
(Jiang、Liu 和 Wu[ 83 ]))Jiang、Liu 和 Wu[ 83 ]使用基于 LeNet-5 的 CNN 对时间序列 EVI 曲线进行分类。作者对模型进行了微调,使用基于参数的迁移学习,利用时间序列 EVI 曲线在 MNIST 数据库上训练该模型来检测手写数字。Jiang, T.; Liu, X.; Wu, L. Method for Mapping Rice Fields in Complex Landscape Areas Based on Pre-Trained Convolutional Neural Network from Hj-1 a/B Data.ISPRS Int. J. Geo-Inf.2018,7, 418. [CrossRef]
基于块的作物分类方法的主要缺点之一是小特征可能会在最终分类中被平滑和错误分类。
。
。
。
(全卷积网络(FCN))
2015 年,一种名为 FCN 的新型 CNN 方法问世,该方法使用卷积层处理输入图像并生成相同大小的输出图像。该方法使用整幅图像作为输入,提取不同抽象级别的特征,并对特征进行上采样,以在网络的下一部分中使用双线性插值、反卷积层和来自更早的、空间上更精确的层的特征等技术恢复输入分辨率。
U-net [ 112 ] 是一种广泛使用的具有跳过连接的 FCN 架构。它也经常用于作物测绘。
Du 等人[ 113 ]以及 Saralioglu 和 Gungor[ 114 ]的论文将 FCN 用于作物测绘的典型例子。
Adrian、Sagan 和 Maimaitijiang[ 80 ]使用 3D U-net 从时间和空间维度提取特征。
值得注意的是,FCN 主要用于高分辨率图像。
Mullissa 等人[ 115 ]、La Rosa 等人[116]和[ 116 ]、Chamorro Martinez 等人[ 117 ]和 Wei 等人[ 118 ]将 FCN 应用于合成孔径雷达(SAR)图像中农作物的分类。
Chew 等人[ 119 ]使用 VGG16 架构和公开的 ImageNet 数据集对其模型进行预训练,然后将其输入到无人机(VAG)图像中。
.
.
(一维卷积神经网络(1D CNN)在时间或光谱维度上的应用)
一维卷积神经网络(1D CNN)在时间或光谱维度上的应用也被用于作物制图和产量预测。
Zhong、Hu 和 Zhou [ 82 ] 证明 1D CNN 可有效且高效地用于对多时相影像进行分类。作者比较了 1D CNN 与 RNN 的输出,使用多时相 Landsat EVI 数据对夏季作物进行分类。在实验中,1D CNN 表现出比基于 CNN、RF 和 SVM 的方法更高的准确度和 FI 得分。该实验证明了 1D CNN 通过表示时间特征对作物进行分类的能力。
(缺陷)然而,这种方法的局限性在于它没有考虑卫星图像的光谱和空间信息。
Zhou 等 [ 120 ] 使用了基于对象的图像分析,这是公认的用于作物制图的高分辨率图像分类方法。作者使用分割算法对 Sentinel-2 影像进行分割,并使用 1D CNN 对分割的平均光谱矢量进行分类。
(缺陷)这种方法利用片段的平均值来捕捉空间信息,但仍然没有对时间关系进行建模,从而提高准确性。
。
。
(RNN)
RNN 模型是第二广泛使用的模型,因为它们在超过 22% 的已综述研究中得到应用。
事实上,RNN 是产量预测的首选方法。
超过 40% 的已综述产量预测研究使用了 RNN。
当涉及时间维度时,RNN 是农业监测的首选方法 [ 47 ]。
LSTM 是 RNN 的一种,它可以有效地从多时相图像中学习时间特征,以进行作物制图 [ 121 , 122 ] 和产量估算 [ 5 , 79 , 88 ]。
Rußwurm 和 Korner [ 123 ] 提出了一种用于时间特征提取的 LSTM 模型,以对多类作物类型进行分类。
徐等 [ 122 ] 使用 LSTM 模型学习时间序列光谱特征,以进行作物制图。
作者还研究了该模型在美国玉米成熟区 6 个地点之间的空间转移,发现该方法可以学习跨区域的通用特征表示。
(RNN 的缺陷)然而,循环神经网络模型通常不能用于学习空间特征表示。(
RNN 更适用于处理时间序列数据,能够有效地学习时间维度上的特征。然而,在学习空间特征方面,它可能不如其他专门设计用于处理空间信息的模型或方法有效。
例如,在作物制图和产量预测等任务中,空间特征对于准确理解和分析作物的分布和生长情况非常重要。虽然 RNN 在某些情况下可以用于这些任务,但在处理空间特征时可能不如其他模型表现出色。)
。
。
(MLP,多层感知机分类是很基础的算法了,主流肯定不会用这种)
尽管 MLP 并不特别适合阵列数据(如 RS 和环境数据),但一些研究也使用了 MLP。
例如,Maimaitijiang 等人 [ 72 ] 使用完全连接的前馈神经网络和数据融合进行产量预测。他们研究了融合光谱、作物高度、作物密度、温度和质地等数据在输入和中间阶段对大豆产量的影响。
Chamorro Martinez 等人 [ 117 ] 使用贝叶斯神经网络预测产量并发现与预测相关的不确定性。在贝叶斯神经网络中,神经网络的权重不是固定的,而是由概率分布表示。
AE 是一种无监督的深度学习技术,在一些作物制图应用中得到广泛使用 [116、124、125 ]。在这些研究中,AE 用于学习压缩并改进卫星数据的表示,然后使用其他方法对这些数据进行分类。
。
。
(包含多种架构的混合模块)
包含多种架构的混合模块用于学习空间、光谱和时间特征,以改进决策。
在混合模型中,不同的架构用于学习不同领域的特征。这些模型要么合并从两个网络获得的高级特征,要么将一种架构的输出特征用作另一种架构的输入。
为了联合建模来自多时间图像的空间背景和时间信息,使用了 RNN 和 CNN 的组合[ 42 , 117 ]。
Ghazaryan 等人[ 126 ]发现,在预测多时间、多光谱和多源图像的产量时,混合模型在 3D CNN、LSTM 以及 CNN 与 LSTM 的组合中提供了最高的准确率。
Zhao 等人[ 127 ]首先使用 LeNet-5 [ 128 ] 模型和迁移学习方法对红、绿和红外图像进行分类,然后在第二步使用带有物候信息的 DT 模型改进分类结果。
虽然这种混合方法提高了水稻测绘的准确性,但该方法在更大规模上实施可能具有挑战性,因为决策规则是局部的,必须通过实地调查来确定。(这意味着这些规则是基于特定区域的实地调查得出的,可能不适用于其他地区或大规模的情况)
。
。
(注意力机制)
近年来,注意力机制在深度学习作物制图和产量预测模型中也变得流行起来。
带有注意力机制的 LSTM 模型被用来提高产量预测模型的通用性,并确定不同变量对产量的贡献 [ 102 ]。
注意力机制还被用来识别作物制图的重要特征 [ 103 ]。
Wang 等人 [ 129 ] 声称,通过整合注意力机制和地理信息可以改进作物制图,因为它可以减少地理异质性的影响,并防止考虑不相关的信息。
Seydi、Amani 和 Ghorbanian [ 84 ] 实现了空间和光谱注意力机制来提取与作物制图相关的隐藏特征。
基于自注意力的 Transformers 也被应用于作物制图,这种 Transformers 被发现可有效处理序列数据。
Rußwurm 和 Körner [ 130 ] 得出结论,Transformers 在处理原始时间序列 RS 数据中的噪声方面更为稳健,并且对其分类更为有效。
Reedha 等人 [ 131 ] 使用 Visual Transformer (ViT) 模型对无人机拍摄的航拍图像进行分类,并实现了与 CNN 类似的准确度。作者还声称,当标记的训练数据集较小时,ViT 模型可以比最先进的 CNN 分类更好。为了评估其性能,DL 模型通常与 ML 方法(例如 SVM、RF 和 DT)进行基准测试。
。
。
。
4.6. 训练数据
深度学习模型的精度和泛化能力取决于训练数据的质量和数量[ 39 ]。训练数据不足会导致模型过度拟合,影响预测精度。
作物制图的大部分训练都是通过实地考察收集关注区域的作物类型标签进行的(表4)。

实地考察是一个耗费人力和时间的过程。
实地调查之后,农田数据层(CDL) 成为作物分类模型的主要训练来源。CDL 是美国的地理参考、特定作物的土地覆盖地图[ 141 ]。它使用地面真实数据和中等分辨率图像制作而成。CDL 的分辨率为 30 米。它由美国农业部(USDA)每年发布。
可以推断,在世界其他地方开展这样的研究具有挑战性,因为没有这样的标准数据。
只有三项研究使用了除 CDL 以外的政府提供的数据。
训练数据的另一种方法是对更高分辨率图像进行视觉图像解释。
。
。
基准数据(例如加州大学默塞德分校土地利用数据集、NWPU-RESISC45 数据集、Campo Verde 数据集和 Breizhcrops)也可用于 RS 分析,并被用于测试一些作物制图研究中的模型。
(Crowdsourcing)众包 是另一种训练数据来源。Wang 等[ 142 ]使用从农民那里众包的作物类型数据来训练网络。Saralioglu 和 Gungor[ 114 ]创建了一个网页界面来收集作物制图的训练数据。
然而,众包方法所带来的挑战是如何为贡献者创造激励或动机。
此外,这些数据的验证是另一个挑战。谷歌街景图像也能提供一种高效、经济的方式来提供地面参考,以训练 DNN 进行作物类型制图[ 143 ]。
。
。
美国农业部国家农业统计局提供的县级产量统计数据和从田间收集的产量数据是训练 DL 产量预测最常用的数据(表 5)。

表中将美国农业部的产量统计数据与其他政府数据源分开,以突出其使用频率。
田间规模产量预测的目标数据是在收获期间收集的,由收割机收集[ 73 ],或通过每个产量地块的加权谷物收集[ 72 ]。
田间数据对于田间预测至关重要。
地方管理机构准备的数据可能无法提供置信度和准确性。
美国可以获得美国农业部的县级产量数据,而加拿大可以获得 CISA 数据。
但是,世界其他地区没有这些数据。
。
。
作物制图[ 113 ]和产量预测研究[ 75 ]也使用了旋转和翻转等数据增强技术,以进一步扩大数据并确保模型不受旋转和翻转的影响。
一些作物制图研究使用了领域自适应技术[ 144 ]和弱监督学习[ 145 ]来解决训练数据稀缺的问题。
Wang等[ 145 ]的结论是,如果有效使用训练标签,即使在训练数据稀缺的情况下,CNN在作物制图方面的表现也能优于其他ML方法。
作者使用两种类型的训练数据(单个地理标记点(像素)和图像级标签)来训练U-net。这种训练方法给出了令人满意的结果,证明了弱监督的适用性。该模型应针对不同地区和作物类型进一步验证,并可使用多时间特征和具有时间学习能力的DL模型进行改进。作物类型标签和历史产量数据的稀缺是开发可靠、准确的作物测绘和产量预测的深度学习模型的主要障碍。
4.8 输出规模
作物制图和产量预测研究在不同尺度上实施。
作物监测研究的应用取决于输出的尺度。
虽然区域研究有助于在国家和区域尺度上监测作物生产,但田间内的变异性对于为特定田间决策提供信息是必要的[147,148]。
输出的尺度取决于输入和目标数据的分辨率。
在大多数作物制图研究中,每个像素或像素组被分配一个作物类别。
田间边界的精度和泛化取决于遥感数据的空间分辨率。
。
我们将产量预测研究分为两类,即田间级别和县级或区级。
几乎70%的产量预测研究是县级水平的,其余是田间级别。县级/区级作物产量统计数据通常用于县级规模的产量预测研究。相比之下,从农民和收割机收集的田间数据用于田间规模的研究。精确的产量数据可用于在尽可能好的尺度上进行预测。
值得注意的是,所使用的平台和研究的尺度是相关的。
在所有基于无人机的产量预测研究中都估计了田间级别的产量。
县级产量预测研究主要在美国进行。这可能是因为美国农业部产量数据的可用性。
。
。
4.9. 评估指标和性能
在所审查的作物绘图研究中最常用的评估指标是 overall accuracy, kappa statistics, precision, recall and F1 score. The majority of the studies used more than one metric to evaluate performance.
均方误差 (MSE)、根 MSE (RMSE)、判定系数 (R 2 )、平均绝对误差 (MAE) 和平均绝对百分比误差 (MAPE) 是评估所审查的产量预测模型的常用指标