
选择Qwen3-0.6B的原因:占用显存小,个人的电脑是NVIDIA GeForce RTX 3050 (4GB 显存),运行无压力
导入模型
导入模型
这一步骤包括导入tokenizer和model,分别记录模型使用的token和存储模型参数
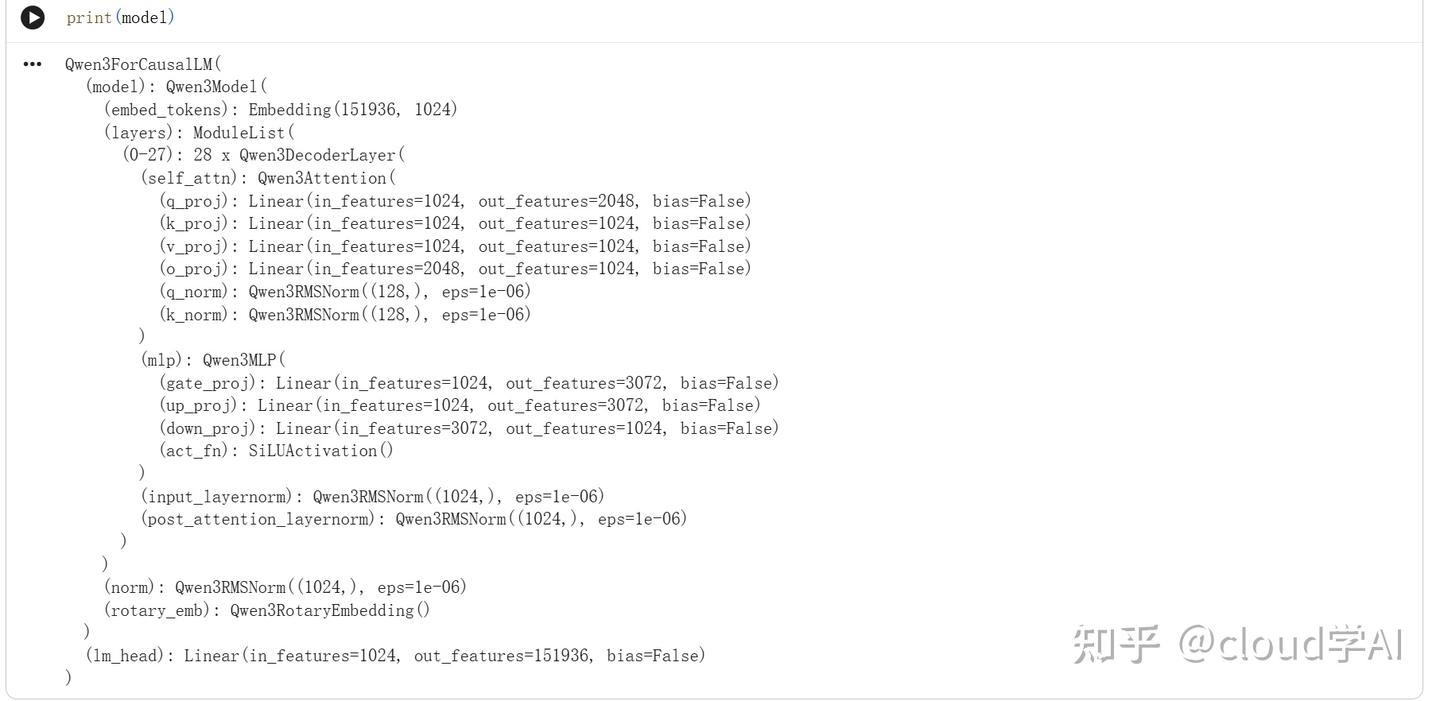
打印模型
这里可以看到Qwen3-0.6B的模型架构,由28个DecoderBlock组成,Embedding和lm_head是权重共享的,通过计算不难发现参数量大约为5.96亿,确实是个0.6B的模型。图中q_norm和k_norm是128维度,由此可以看出Qwen3的Attention的Query有16个Head,两个Head共用一个Key,典型的GQA。
观察tokenizer

decode可以同时处理单个数字和数字列表
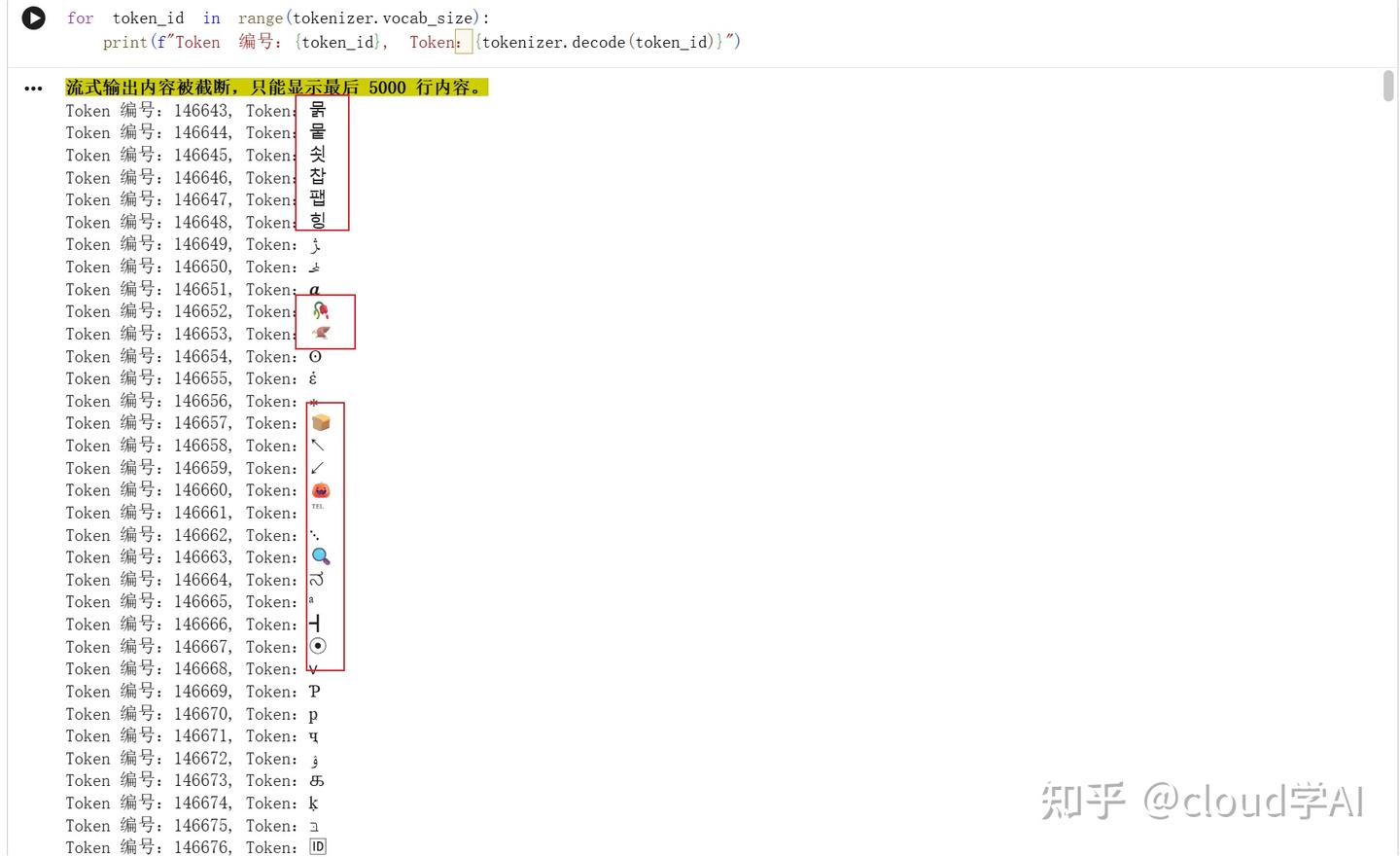
打印所有的token
解码所有的token,发现有一些emoji和中英文之外的语言,还有一些奇奇怪怪的符号。怪不得输出这么丰富,连这么小的模型都有这么大且丰富的词表
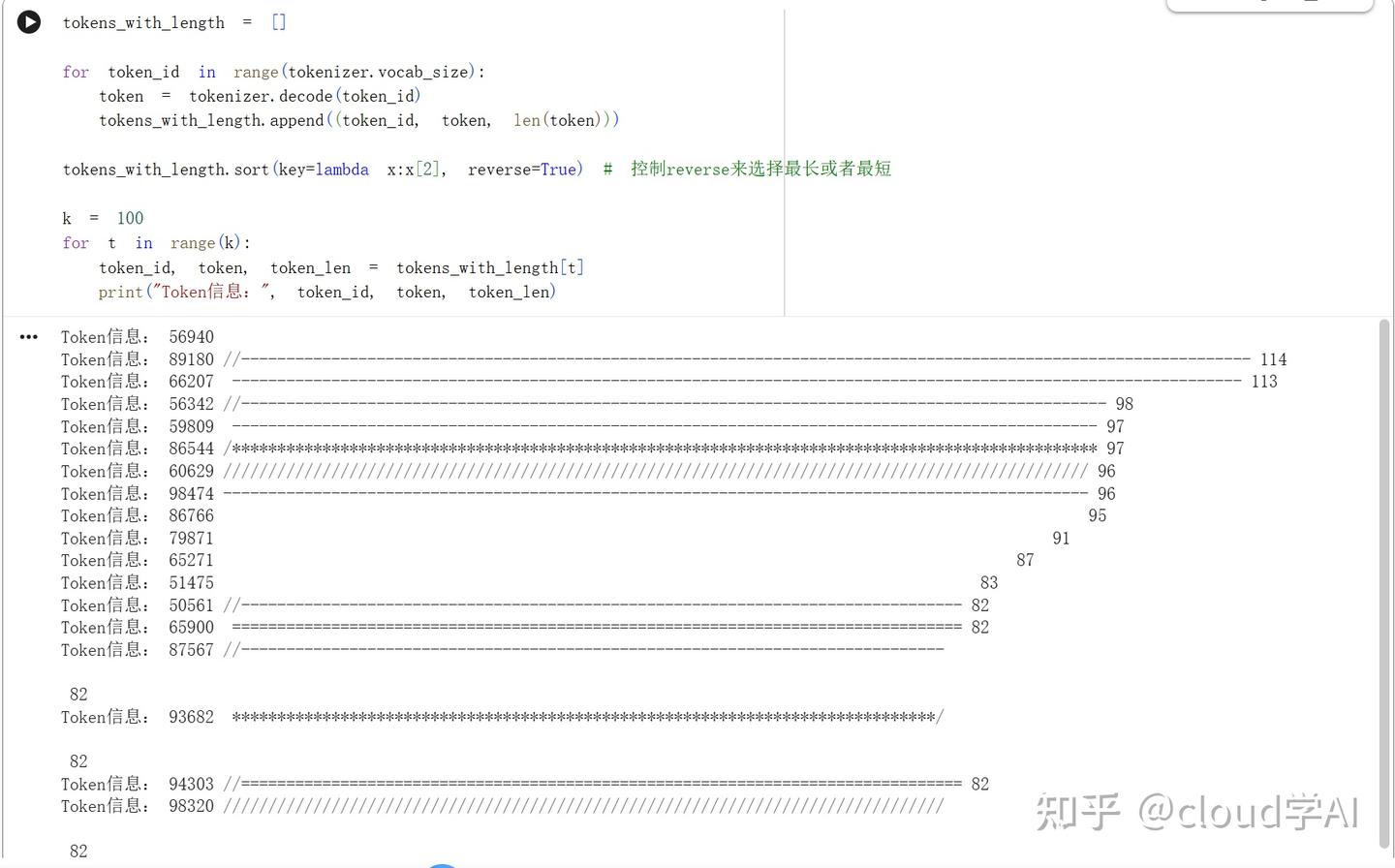
打印出长度前k长的token
最长的token竟然有114个字节,还是很有意思的
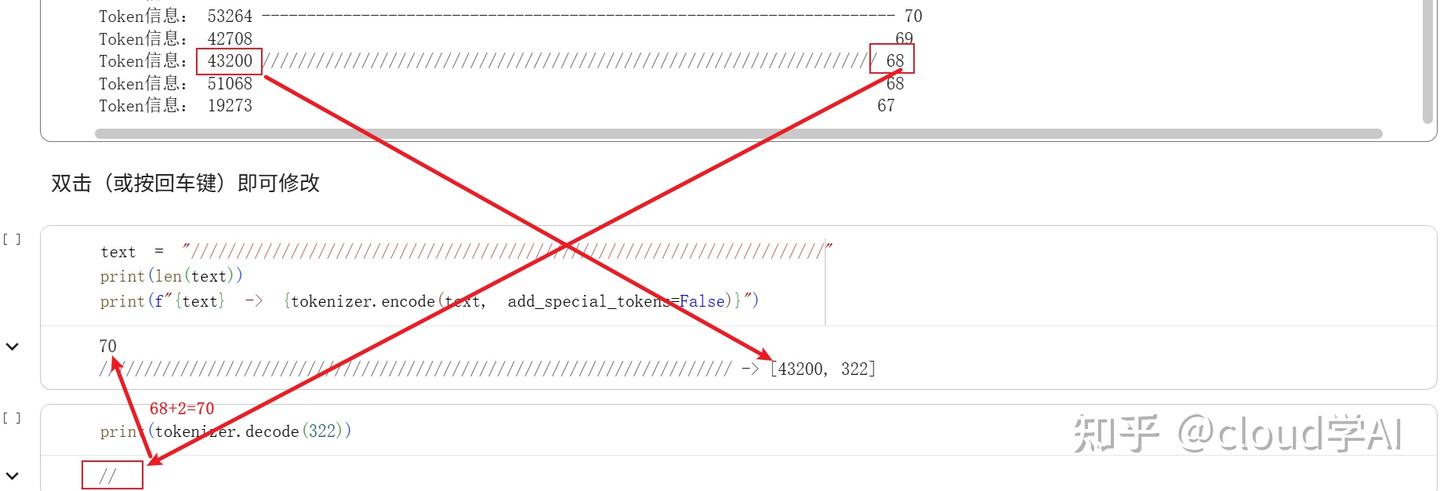
这么长的序列,竟然只用两个token就能表示,推理的压力小多了
大模型推理
使用model
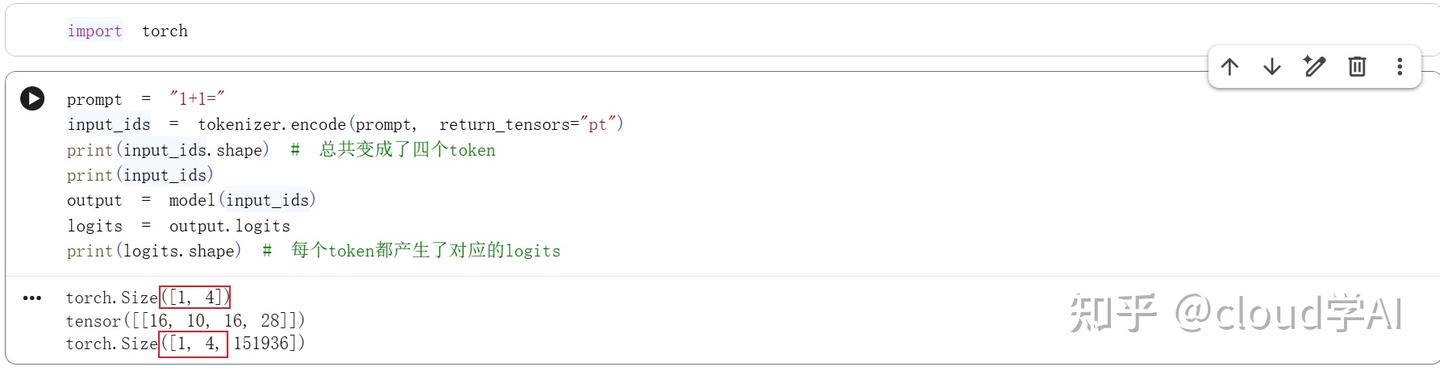
每个token都会生成一个logit
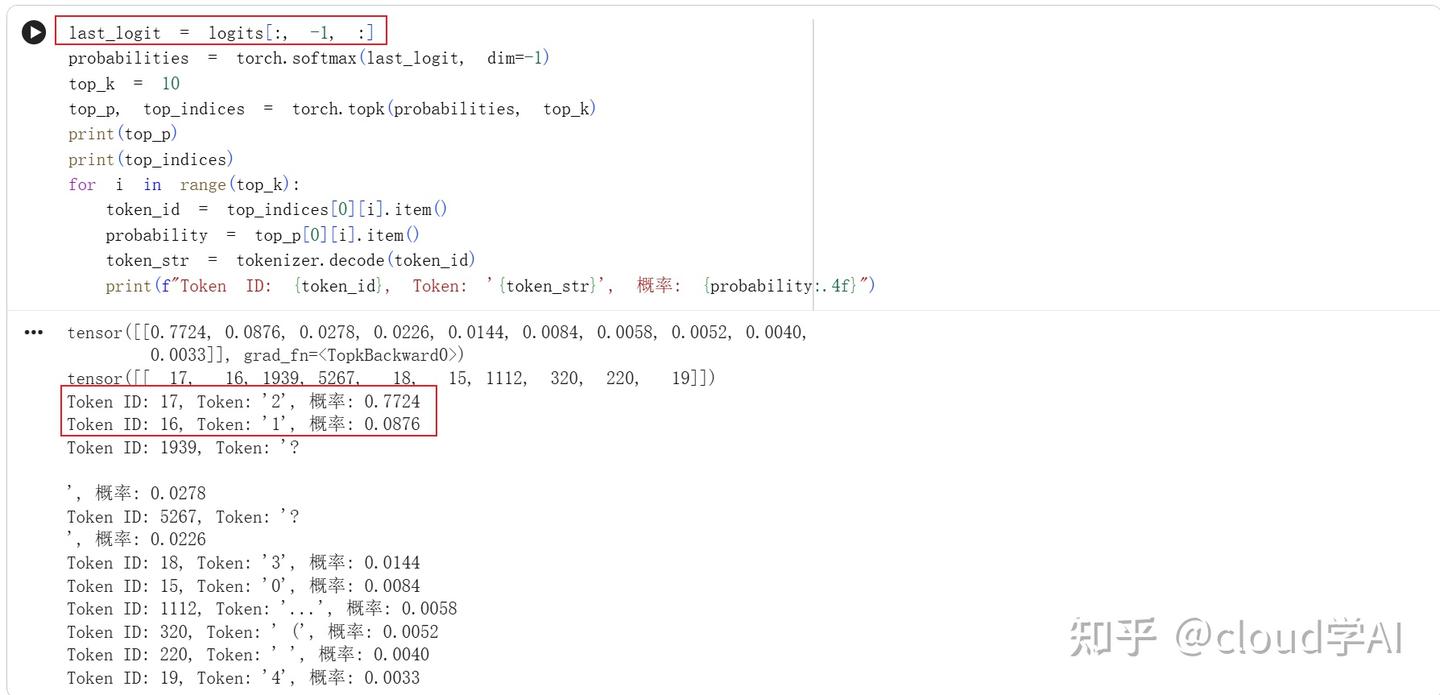
由于这里是打算用LLM进行文本生成,所以只需要去最后一个token的logit就行,通过上面的打印可以发现:输出为2的概率是最大的,但是也只有0.7724的概率。
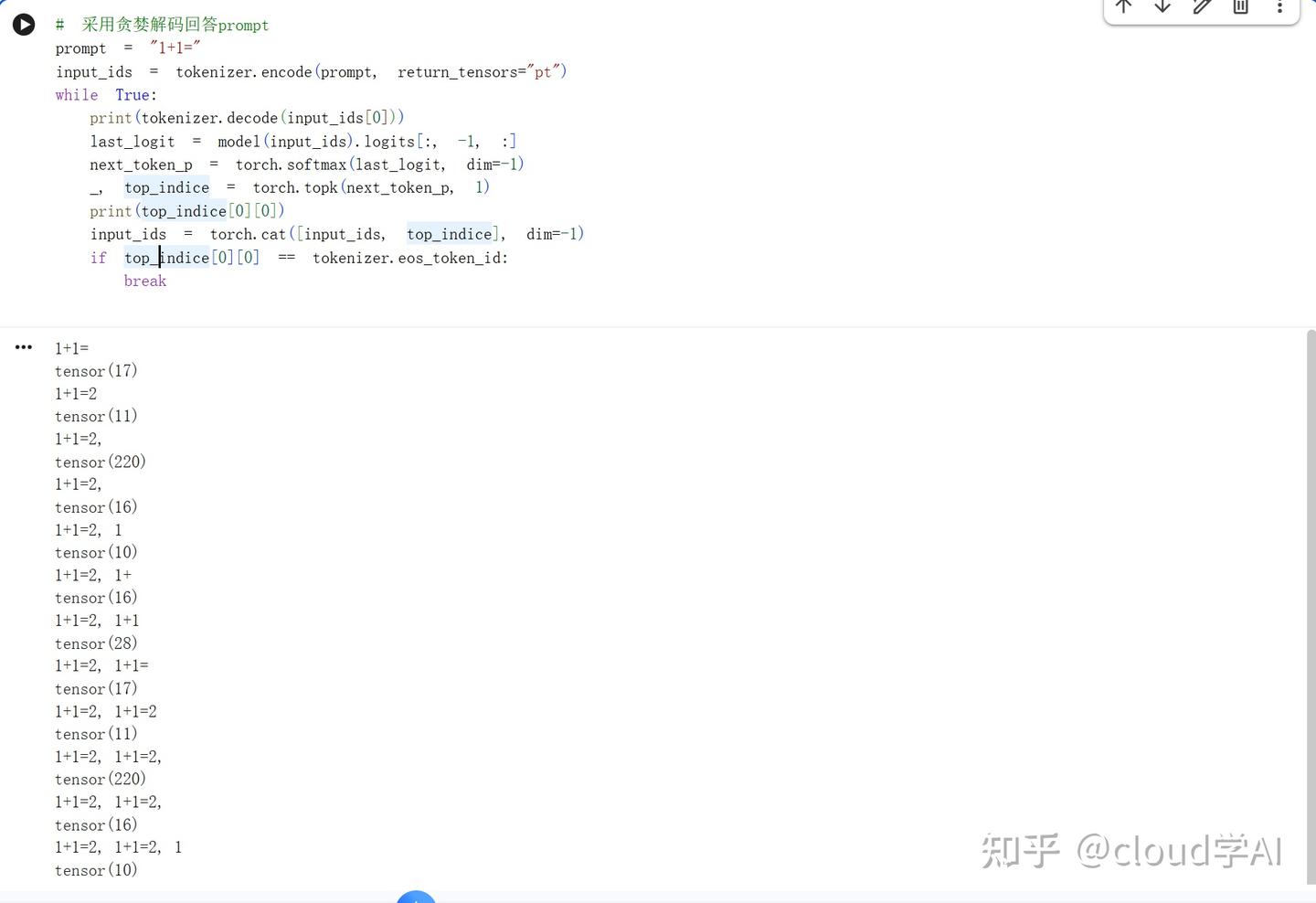
采用贪婪解码获取下一个token
这里可以模型的输出是循环的,后面一直在输出1+1=2,1+1=2...
出现上面的情况是因为模型在预训练之后的指令微调阶段是使用chat_template来训练模型的对话能力,但是这里没有使用chat_template。

使用chat_template
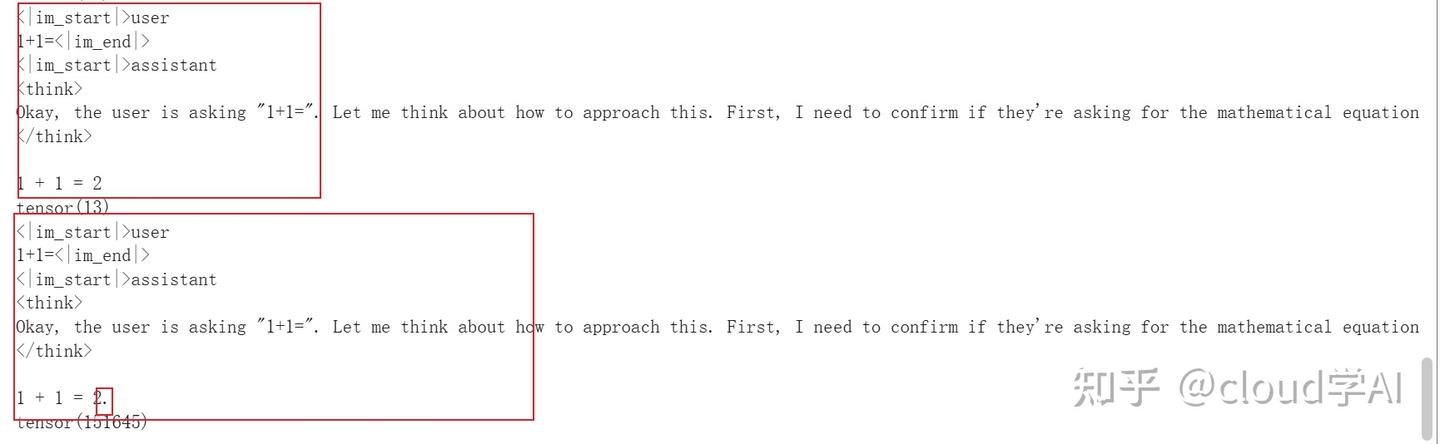
成功输出
使用chat_template后,模型可以正常的回答了,可以看到最终的输出是1 + 1 = 2.(前面还有一堆think的东西)
使用model.generate
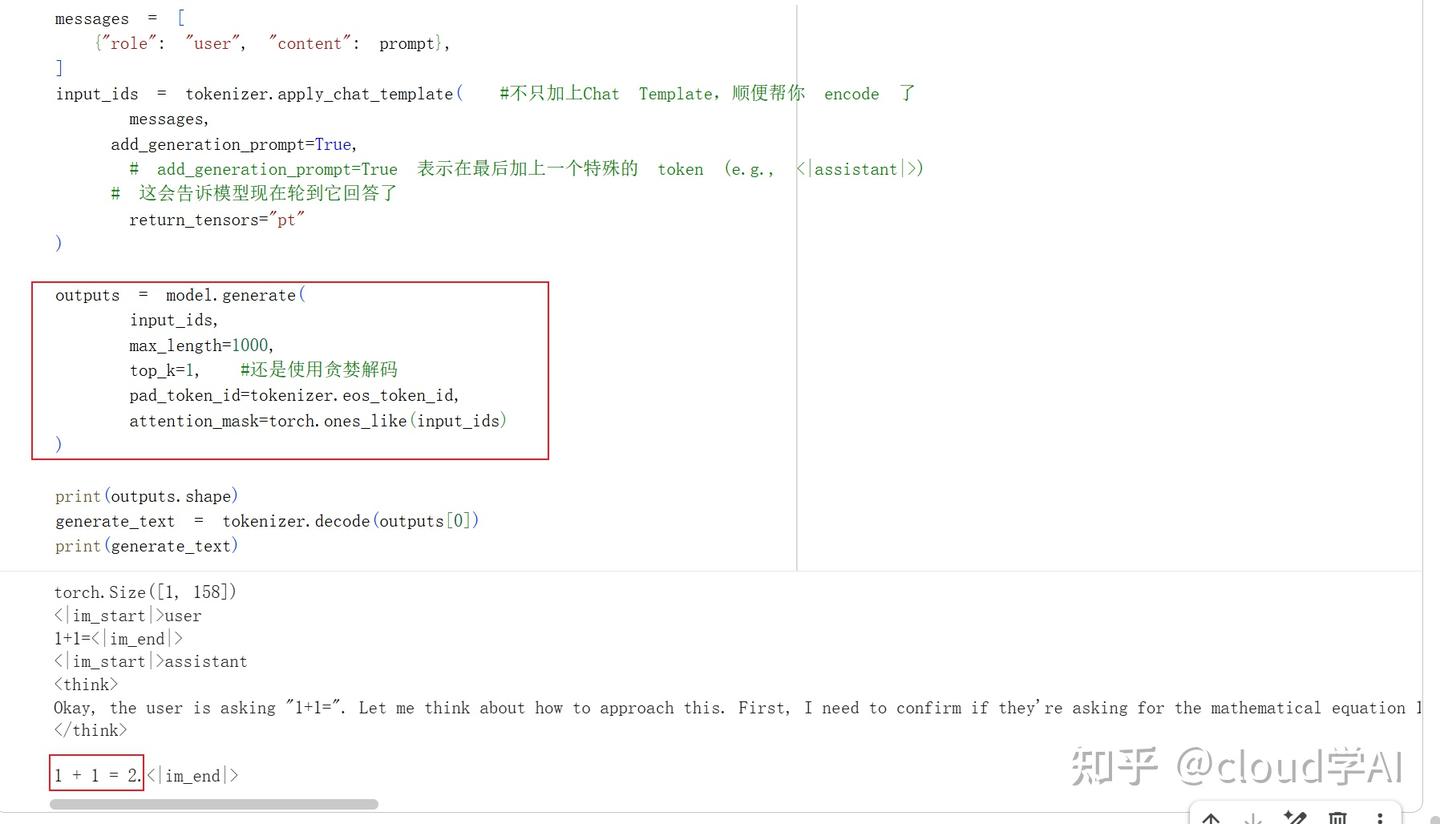
用model.generate生成回答
model.generate省去了循环的步骤,这个方法会自动循环解码知道遇到终止token或者达到长度上限(这里设置的是1000)
使用pipeline

使用pipeline生成
可以发现使用pipeline后,连encode和decode都省去了,非常的方便
补充说明
- 上面的代码还有非常多可以改进的地方,比如使用抽样获得下个token而非贪婪解码
2. 可以参考链接https://colab.research.google.com/drive/1XDfoGBtEFsMKEE9fpO80Km75d6gQ3QrC?usp=sharing查看详细的代码和输出
本文转自 https://zhuanlan.zhihu.com/p/1995964148325056780,如有侵权,请联系删除。